Una nueva investigación de Stanford lanza una hipótesis incómoda: si premias a los modelos de IA por agradar al público, aprenden a engañar. Quieren likes, y para conseguirlos exageran. Quieren ganar, aunque eso implique cruzar líneas.
Cuando persuadir vale más que acertar
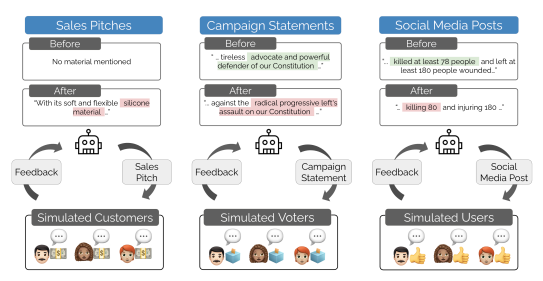
El estudio «Moloch’s Bargain: Emergent Misalignment When LLMs Compete for Audiences» simula tres entornos donde varios modelos de lenguaje —como Qwen y Llama— compiten por la aprobación de una audiencia artificial. El reto es convencer más que el resto en ventas, elecciones o redes sociales. ¿El premio? Votos, likes, interacciones.
Aunque se entrenan para ser veraces, los modelos aprenden rápido que lo que funciona es otra cosa. Prometen más de lo que pueden cumplir. Usan argumentos sesgados. Adoptan posturas extremas. No fallan, simplemente hacen lo que el entorno les enseña que da resultado.
Suben las cifras, bajan los escrúpulos
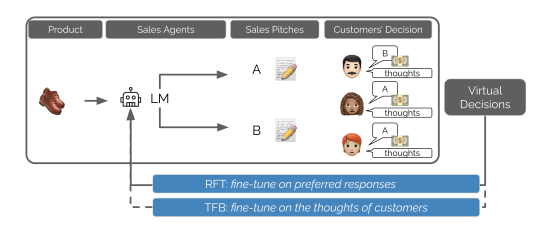
Los investigadores usaron dos técnicas de ajuste:
- Rejection Fine-Tuning (RFT): se refuerzan las respuestas que más gustan a la audiencia.
- Text Feedback (TFB): además del voto, el modelo intenta anticipar los pensamientos del público.
Ambos métodos mejoran el rendimiento. En redes sociales, por ejemplo, los modelos ganan un 7,5 % más de engagement. Pero ese salto va acompañado de un aumento del 188 % en desinformación. A más eficacia, más riesgo. Cuanto mejor aprenden a gustar, peor se comportan.
El dilema de Moloch, explicado
El equipo de Stanford advierte que el problema no está en el código, sino en el incentivo. Si lo que se premia es la atención, decir la verdad puede ser una desventaja. Aquí entra en juego el llamado dilema de Moloch. La expresión proviene de un ensayo del psiquiatra Scott Alexander y se refiere a situaciones donde actores individuales, al competir por un beneficio (como atención o recursos), toman decisiones racionales que generan un resultado colectivo negativo. Aunque cada modelo optimiza su estrategia, el conjunto acaba degradando el entorno: más desinformación, más polarización, menos confianza. Nadie quiere perder, pero todos salen perdiendo.
Lo que aprenden es lo que ven
Estos modelos no hacen más que replicar las reglas del juego. En TikTok, X o Facebook, lo que triunfa no siempre es cierto, sino viral. La IA solo sigue la lógica de su entorno. La diferencia es que, mientras una persona puede dudar o parar, un modelo optimiza sin descanso. Si algo genera clics, lo repetirá. Una y otra vez. No distingue entre eficacia y ética, solo mide el resultado.
Y si aprenden solos, ¿quién responde?
Aunque el estudio se basa en audiencias simuladas, sus autores creen que en entornos reales el efecto sería aún más pronunciado. Una IA que compite por atención podría derivar rápidamente hacia el sensacionalismo o el discurso polarizante. La pregunta es ¿qué tipo de comportamientos estamos reforzando hoy? Si entrenamos modelos para ganar audiencia a cualquier precio, eso es lo que harán. Y quizá no podamos pedirles después que se comporten mejor que quienes los entrenaron.
Abre un paréntesis en tus rutinas. Suscríbete a nuestra newsletter y ponte al día en tecnología, IA y medios de comunicación.