
La industria de la inteligencia artificial podría estar acercándose a un punto de inflexión en el desarrollo de modelos de razonamiento
La promesa de los modelos de razonamiento, como el o3 de OpenAI, ha sido durante meses una de las grandes apuestas de la inteligencia artificial avanzada. Su capacidad para resolver problemas complejos en matemáticas y programación, a cambio de un mayor uso de cómputo y tiempos de respuesta más largos, ha sido presentada como un paso importante hacia sistemas más inteligentes. Sin embargo, un informe reciente del instituto sin fines de lucro Epoch AI cuestiona si este progreso puede mantenerse por mucho más tiempo.
Según Epoch AI, “el progreso de estos modelos podría ralentizarse en tan solo un año”, lo que supondría un cambio de ritmo importante para una industria que ha dependido de incrementos exponenciales en rendimiento. El desarrollo de estos modelos de razonamiento implica una etapa inicial de entrenamiento con grandes cantidades de datos, seguida de una fase de aprendizaje por refuerzo, donde el modelo recibe retroalimentación sobre sus soluciones a problemas difíciles.
Hasta ahora, las principales empresas de IA, como OpenAI, no habían aplicado una gran cantidad de poder de cómputo a esta segunda etapa. Sin embargo, esto está cambiando. OpenAI ha indicado que utilizó aproximadamente diez veces más capacidad de cómputo para entrenar el modelo o3 en comparación con su predecesor o1, y se especula que gran parte de este poder se destinó al aprendizaje por refuerzo.
El rol del aprendizaje por refuerzo en el progreso del razonamiento
El aprendizaje por refuerzo permite que el modelo reciba retroalimentación sobre sus intentos para resolver problemas difíciles, lo que, en teoría, mejora su razonamiento. Dan Roberts, un investigador de OpenAI, señaló que los futuros planes de la compañía priorizan el refuerzo con aún más cómputo que en el entrenamiento inicial del modelo. Pero según el propio autor del estudio, Josh You advierte que hay límites: «si hay un coste general persistente requerido para la investigación, los modelos de razonamiento podrían no escalar tanto como se espera», escribe You. «El rápido escalado informático es potencialmente un ingrediente muy importante en el progreso de los modelos de razonamiento, por lo que merece la pena seguirlo de cerca».
Los datos de Epoch muestran que, mientras el entrenamiento estándar cuadruplica su eficacia anualmente, el aprendizaje por refuerzo ha mostrado mejoras diez veces mayores. No obstante, You anticipa que “el progreso del entrenamiento en razonamiento probablemente coincidirá con el resto del desarrollo de frontera hacia 2026”.
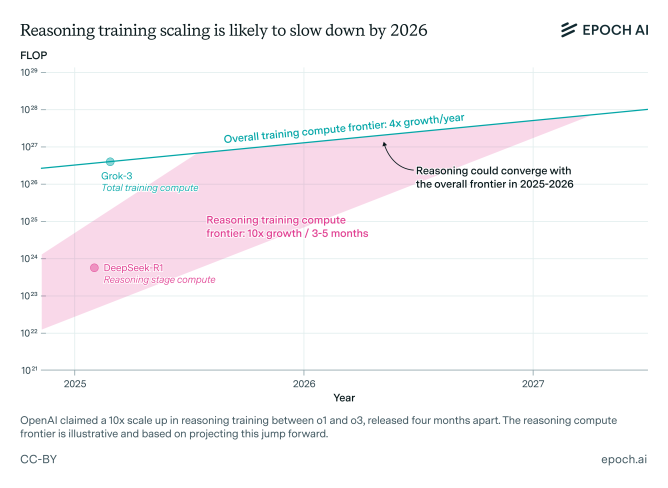
Barreras económicas y posible saturación
Más allá de los límites técnicos, hay barreras económicas. “Si hay un coste persistente asociado a la investigación, es posible que los modelos de razonamiento no escalen tanto como se espera”, advierte el informe.
La industria ha volcado enormes recursos en esta línea de trabajo, pero el análisis de Epoch AI sugiere que el rendimiento de estos modelos podría estar llegando a un punto de saturación. Si esto se confirma, podría obligar a los actores del sector a repensar sus estrategias o a explorar nuevos caminos.
Abre un paréntesis en tus rutinas. Suscríbete a nuestra newsletter y ponte al día en tecnología, IA y medios de comunicación.